
The HVC Operating System
The OS for a data driven VC leveraging agentic AI and live data to automate sourcing, screening and scaling theses driven investing in impactful ventures with solid science.
Being a small team means being economical and being smart with how to set-up (and automate) as much as possible of the fund’s operation with humanity’s newest friends: agents.
The barriers to not knowing have been depleted. The traditional workload has been diminished. Although these are scary times, they also offer a lot of opportunity. We can now basically ‘will anything into existence’ we feel should be there.
And, we feel HVC should be there. Because we have a large group of adrenal patients and too little innovation happening in the field.
We have focused on 4 main domains for automation with help from our ghostly AI friends:
- Research
- Sourcing
- Screening
- Due diligence
Actually, we have published this nice looking HVC Operating System webpage which shows nice moving visuals and how everything moves together. Go there if you want the succinct overview we share with stakeholders in the fund. Stay here if you want my reflection and explanation on it. Disclaimer: I write this (not an LLM) primarily to learn.
Research
This resolves around thesis development. And for HVC thesis development really has to hit two main criteria from our dual-lens:
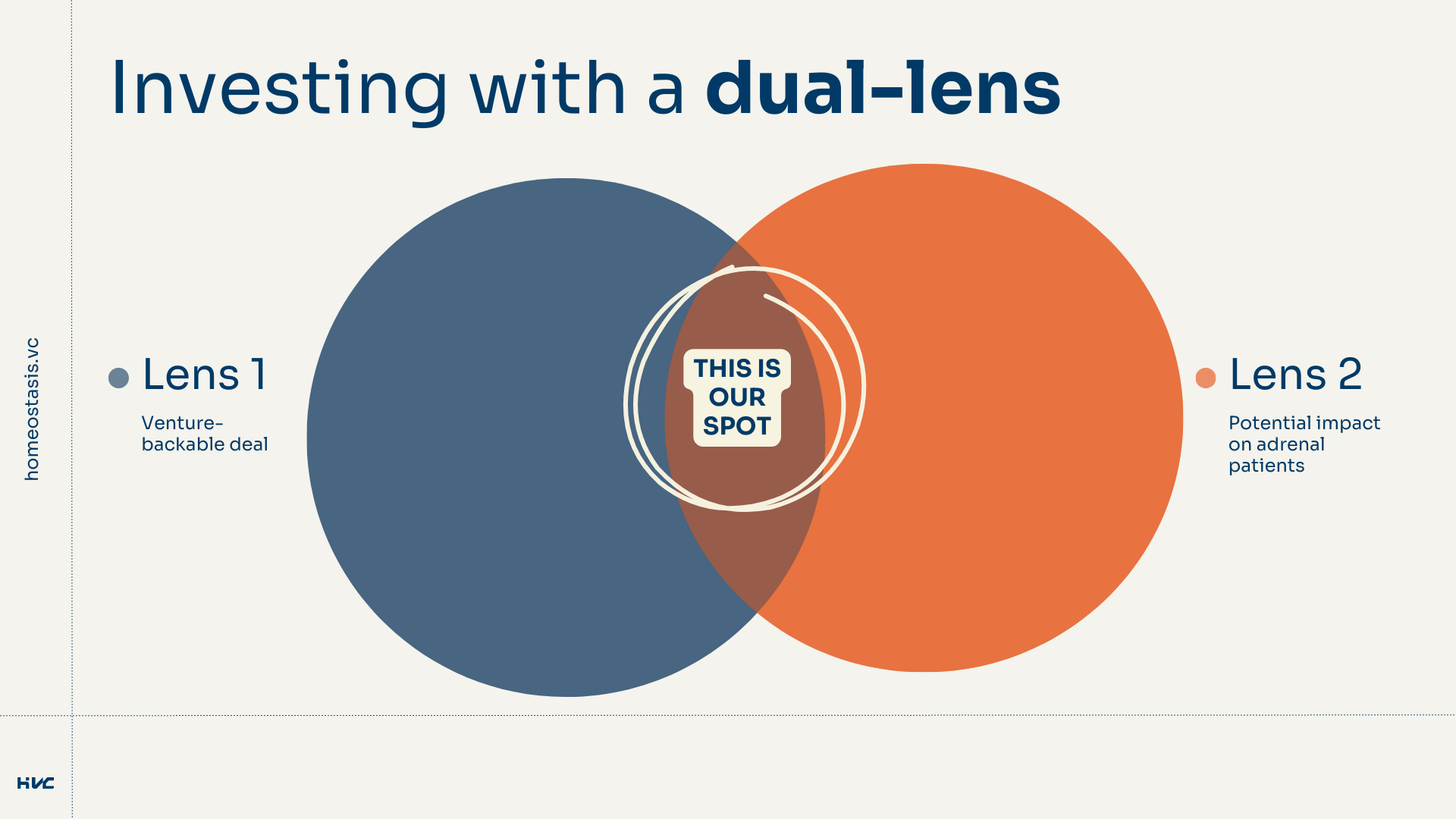
That may result into backing technologies in a technological field that do not target the indications of adrenal patients itself, but the technology being there (in existence) would mean a lot to our patients. Hence, it would be a good thesis for us to say: ‘Circadian Rythims are increasingly interesting for improving fertility [huge market; venture backable], having more tools to understand and act on our circadiam rytym would make a huge change for adrenal patients [adrenal impact].
And there are many such examples. The idea is to have these ideas, science, KOLs, companies, market trends compound over time. And when I say compound I mean 'link’ essentially.
LLMs are especially good at spotting those links considering they are generating and operatinc semantic vectors. If you dump all your (research) notes in a database and ask a LLM to spot links between them, they will be remarkbly good at doing so (but, always check for too creative link-spotting). That means, you can basically upload all your files into Obsidian and ask an LLM to build the links to get a pretty looking (not unimportant) grap view in return. Beyond prettinness, looking at it in such a universe view genuinely makes you see new links.
I used Openclaw to go through all my existing notes, data, emails and make the actual markdown files that eventually formed the universe. This worked well and saved a lot of time.
To iterate on that and have those thoughts expand and compound over time is of course, key. In a way, you are building your own RAGgraph universe.
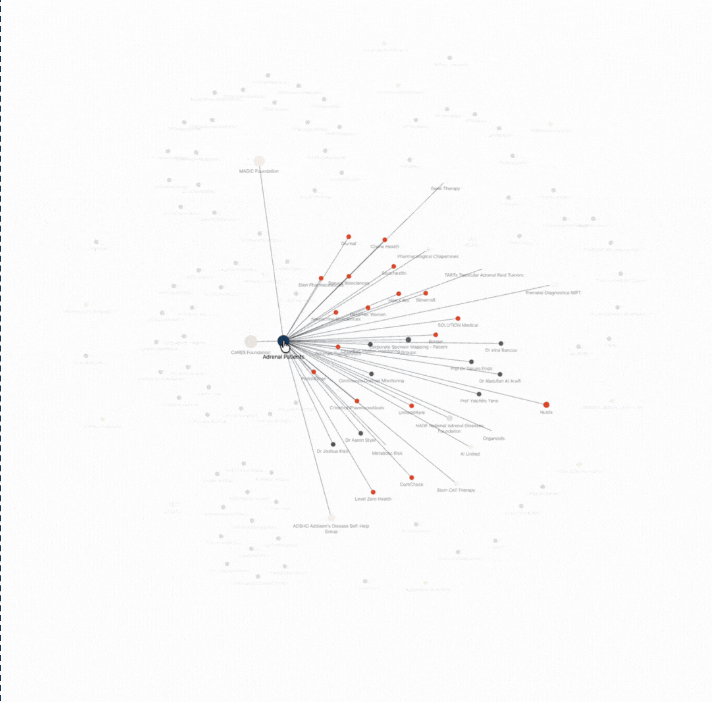
More people, more time, more insights on paper and eventually you will start to see relations that would have been more difficult in a static setting. I think this will be increasingly relevant as our information-load is increasignly so rapidly and not knowing is no longer a thing. It’s seeing how it links up and playing the right angle that is.
Glad tidings to those with the creativity to see and invent the right angles!
Sourcing
This is where the magic happens. The ‘venture industry’, or, the industry of innovators trying to find people that want to back them with money in any way shape or form, is notoriously opaque. There may be 1000s of innovators working on technology that would be a perfect fit for HVC, but I may never even have heard of them. And vice versa. Obviously, I hope that HVC grows into a brand that is well-known within this endocrinology niche, but until that day comes, I need a super-sourcing engine, which can help me find the inventors at the right space in time..
And there she is. Just look at her 😍

To be entirely frank, those tools listed above the visual are almost entirely obsolete now. With a bit of tinkering, any 24/7 agent could do this job. What is most important is giving (and omitting) the right context in the cron job.
Simplified version of the cron job I set-up in Openclaw:
- Every Friday morning 10am, scan your data-sources (Pubmed, and other listed above) for technologies that we deem impactful in Obsidian file X
- Refer to Obsidian file X (with tech domains deemed high impact). This is the most important part, because this is your guidance for picking up the right signals.
- Ensure there are no duplicates with the existing list (in Attio CRM in my case)
- Add to the the list.
That’s it.
Screening
This is where I feel highly inspired by the authors of the DIALECTIC paper and all other builders in the Data Driven VC community. To be honest, for me, it hasn’t been necessary to use this as much, because deal-flow is still small and I am so passionate about this that I’ll basically take any call with founders building something in this space to build the HVC brand, expand the network etc. However, I hope this will be useful for me when greater volumes come in and I can use this for preliminary screening.

Due Diligence
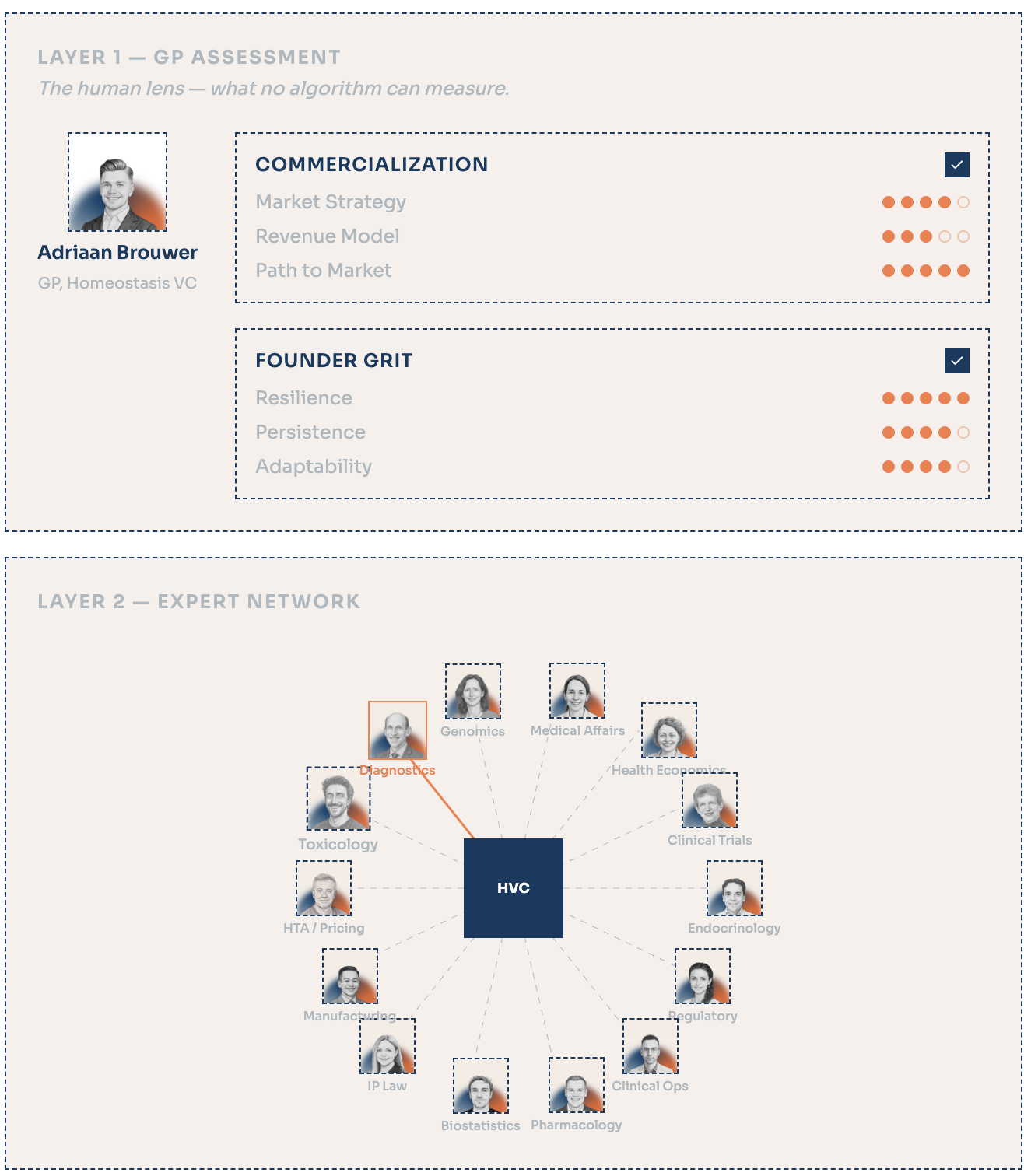
Lastly, we are down to our manual layer. The work that cannot be easily automated. The ‘looking someone into the eye and figuring out if he/she will run through a brick wall or not’. It’s the part that I find the most fascinating. Not much agentic automation to be done here (leaving aside supportive work from our AI friends).
Although, it can be said that we are setting up quite a unique incentive structure for our advisory network. Because we are a specialized fund, focused on one particular niche we can build up deep domain experience and plug in our advisors ‘hands-on’ on a deal-by-deal basis.
And that’s it. For now. No more thoughts to distill.